本文最后更新于:2024年6月18日 晚上
形式语言与自动机考试题型整理
练习试卷可参考哈工大
1.构造DFA/NFA
L={x∣x∈{0,1}+且x满足...}
-
以01、101、1101开头
DFA:要注意qdie状态的设计。以101为例,DFA如下:
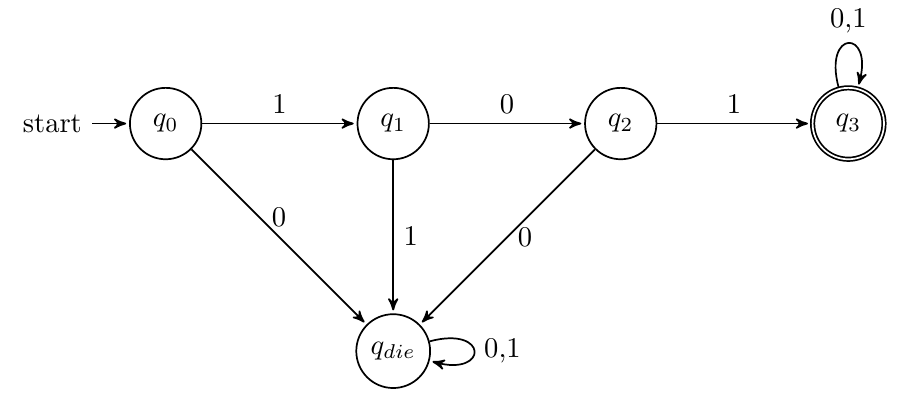
-
包含01、101、1101
DFA:先把包含该串的状态画出来,再考虑其他转移状态的设计
NFA:从每个字母开始猜测
以1101为例,DFA和NFA如下:
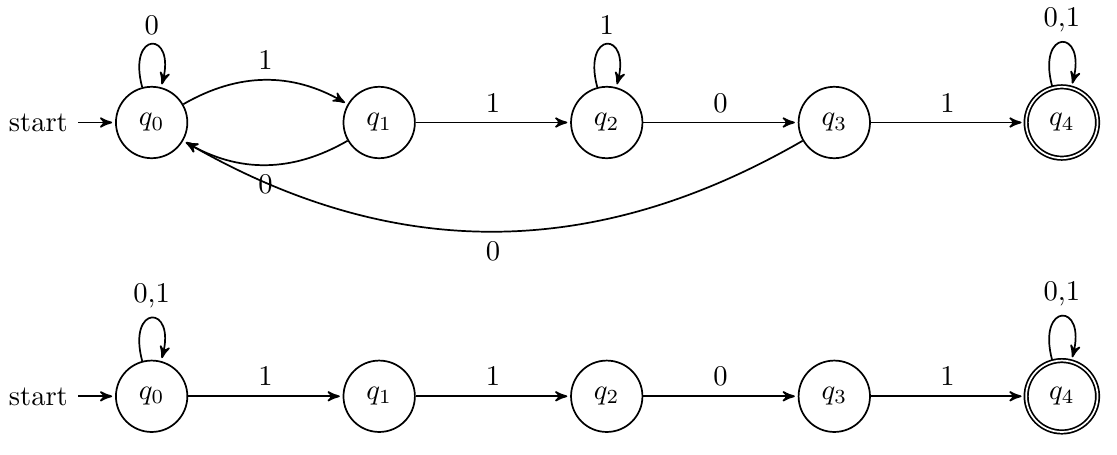
-
以01、101、1101结尾
DFA:先把该串状态画出来,再考虑其他转移状态的设计
NFA:从每个字母都开始猜测
以1101为例,DFA和NFA如下:
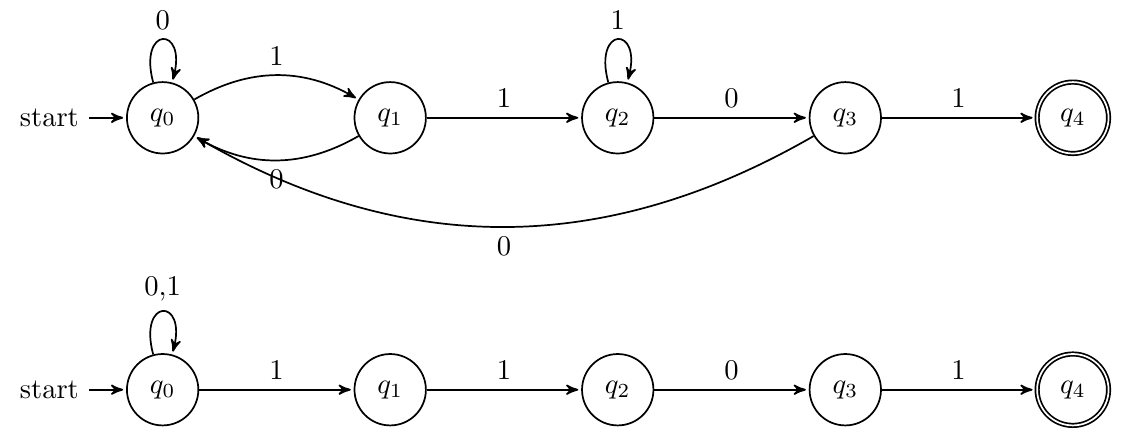
-
不包含00、11、1010
DFA:直接将包含00、11、1010情况中DFA的非接受状态和接受状态互换即可
-
同时含有01和10
- DFA:考虑将首字母分为0/1分别讨论
- NFA:在每个字母的位置分0和1进行猜测即可
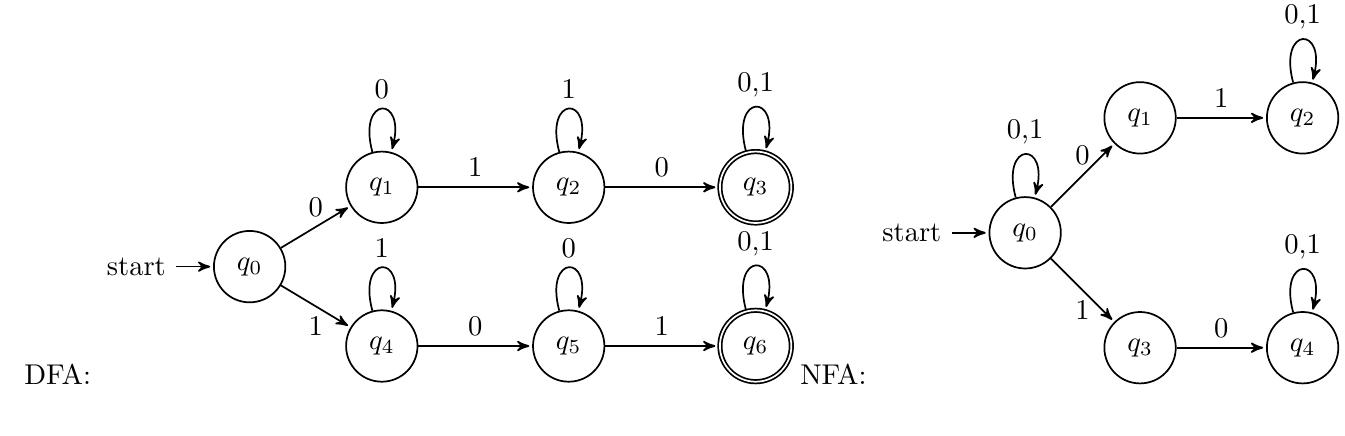
-
同时含有00和11
-
把x看做二进制时,x模5余3
先看一道书上的例题,P36 2.2.6(a):
x以1开头,解释为二进制整数时是5的倍数,如101、1010、1111
-
先不看以1开头,由于任何整数模5,其余数都在0到4之间。我们考虑只针对余数设计状态间转移,即q0/q1/q10/q11/q100四个状态,q0为接受状态。转移规则如下:假设我们当前读到的01串是(y)2=(5a+b)10,0≤b≤4,那么(y1)2=(10a+2b+1)10,(y0)2=(10a+2b)10,其中y1需要判断2b+1是否≤5,即识别到1余数×2+1,识别到0余数×2
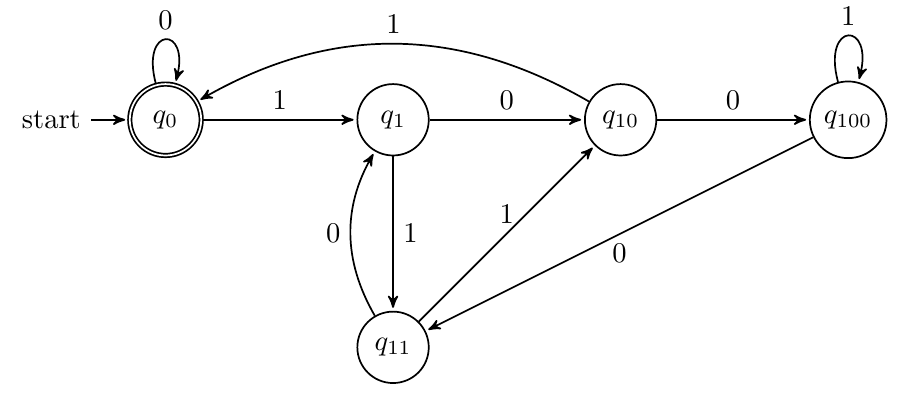
-
加入以1开头,即进入该转移的初始状态为q1,我们可以增加一个初始状态qs,接收0则进入状态qdie,接收1则进入q1
回到此题,显然以q11作为接受状态即可。
如果此题说x是5的倍数的二进制表示,需要考虑判断是否有前缀0,如0000101,不被接受
-
x以1结尾,长度为偶数;以0结尾,长度为奇数
- DFA:可以考虑四个状态,1结尾长度为奇数、1结尾长度为偶数、0结尾长度为奇数、0结尾长度为偶数,可添加一个初始状态,然后在四个状态间进行转移即可
- NFA:先考虑设计奇数、偶数两个状态,奇数状态尝试再识别1达到接受状态,偶数状态尝试再识别0达到接受状态
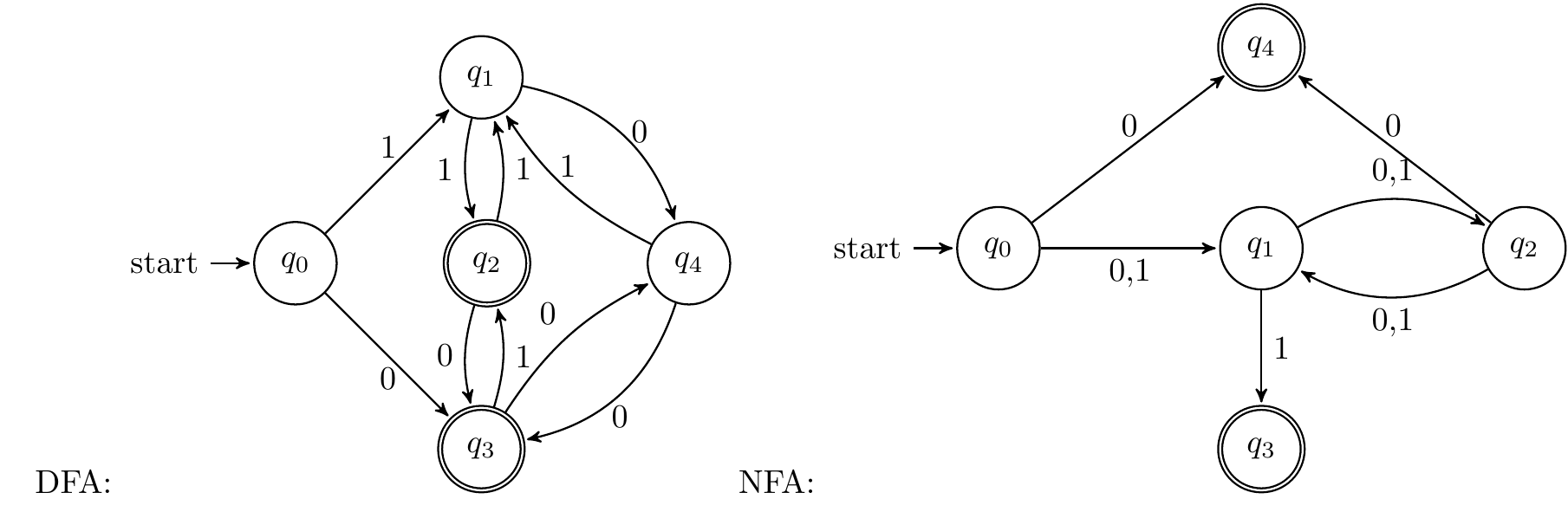
-
x的首字符和尾字符相等
分01讨论即可
-
x是十进制非负数
不接受有前缀0的即可(单个0除外)
-
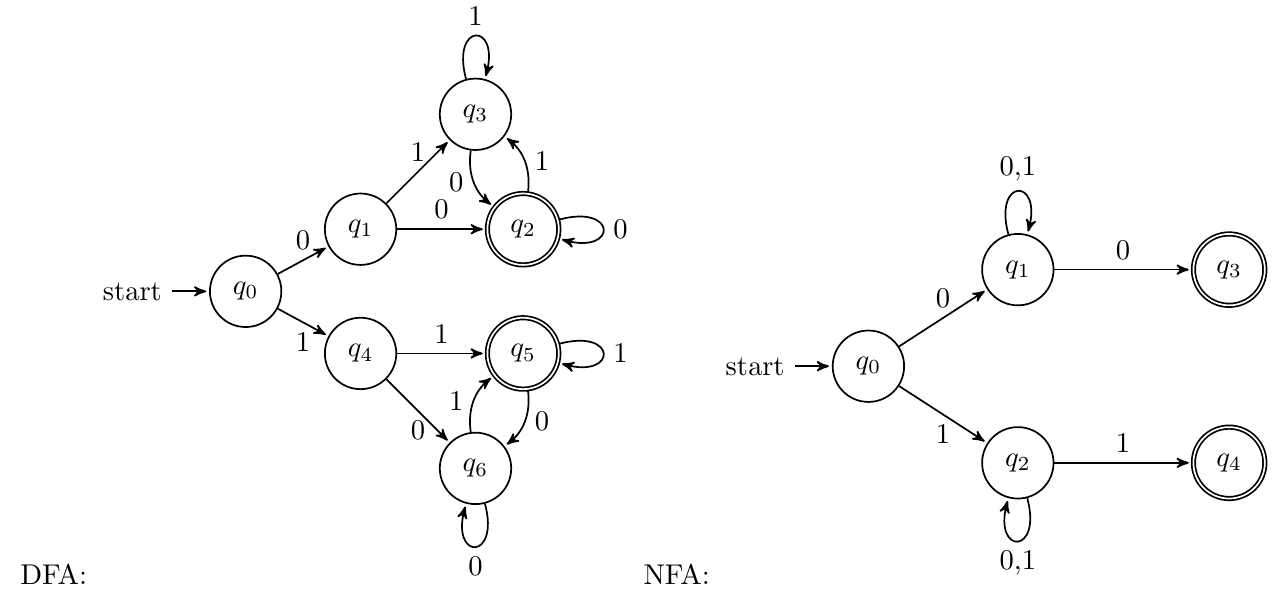
x中0和1个数相等且交替出现
分第一个元素为0/1讨论即可,DFA如下:
-
x中0的个数被2整除,1的个数被3整除
不在考试范围内,可考虑对0构造状态q00,q01,对1构造状态q10,q11,q12,从而构造出2×3=6个状态,接受状态为q00q10
-
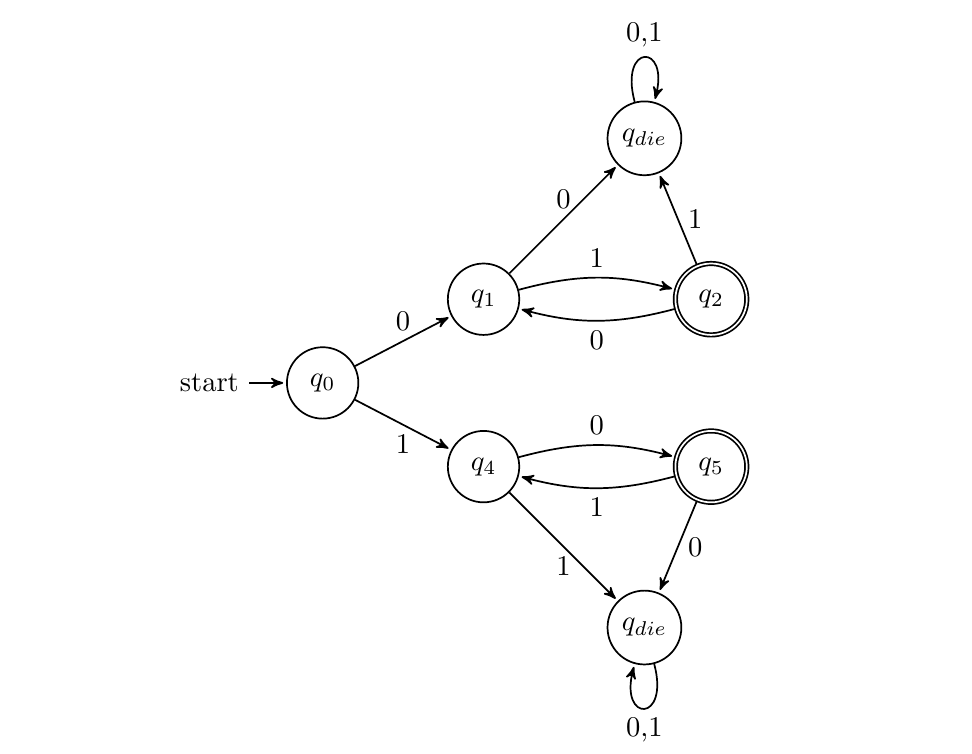
x以01开头或以01结尾(含同时)
DFA:
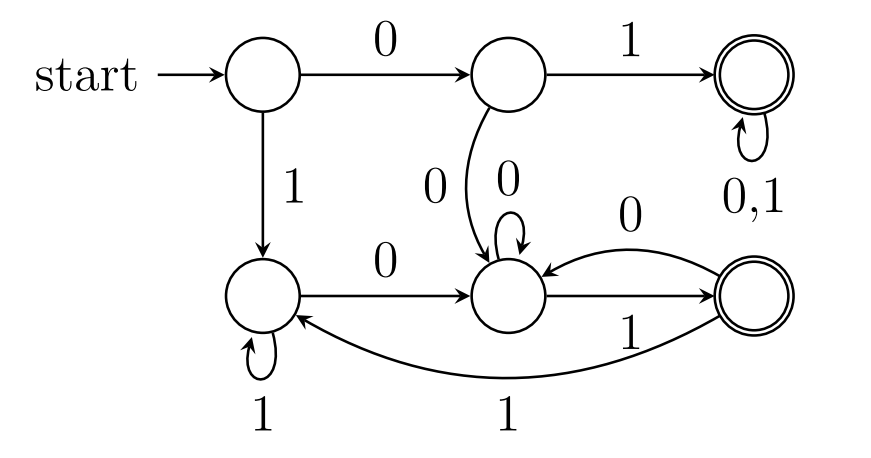
NFA:
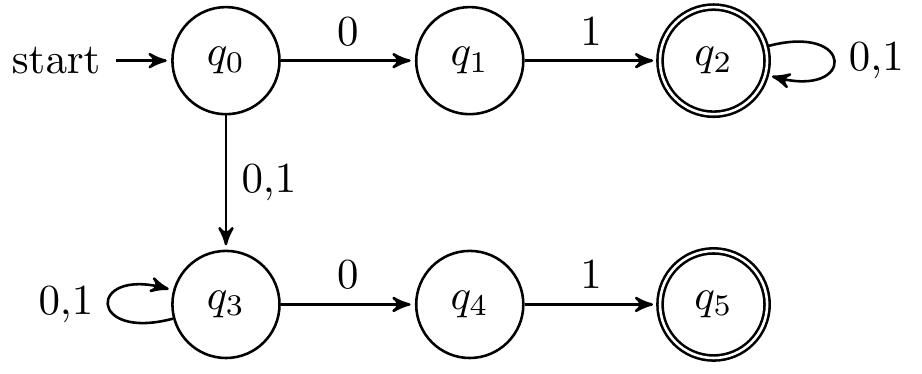
NFA:三种方式均可,第二个NFA可以认为是在x倒数第3个字符是1的基础上得到
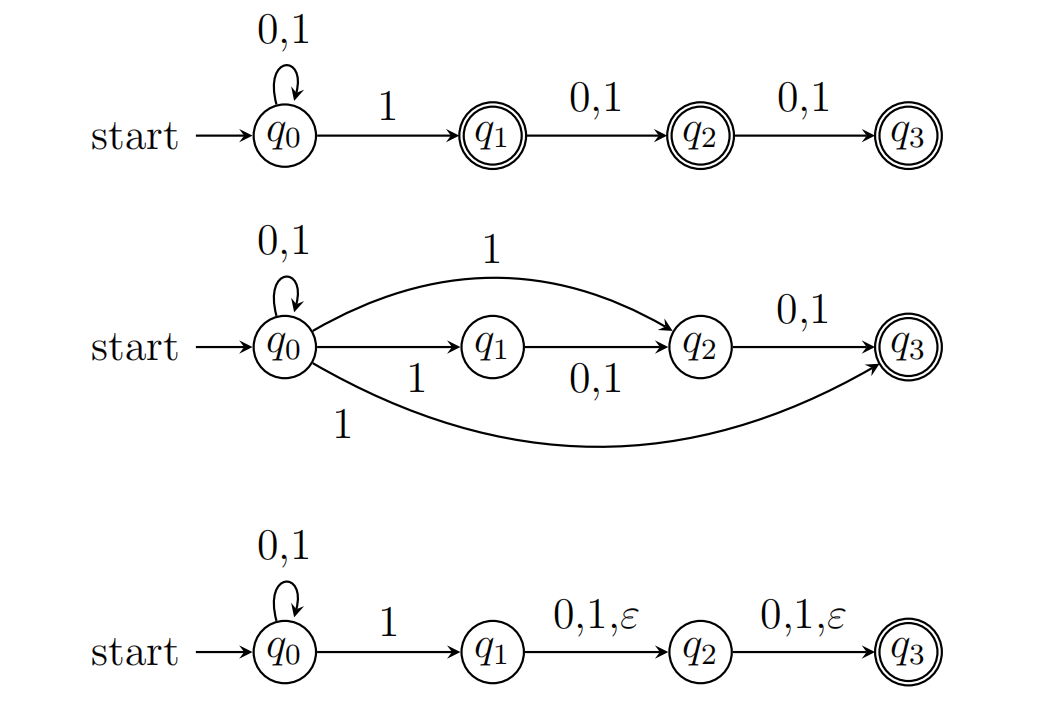
2.DFA算法
2.1 ϵ-NFA2NFA
2.2 NFA2DFA
采用子集构造法
2.2 等价性Equivalence
考的概率比较小,用于判断两个DFA是否定义了相同的语言。方法:构造乘积自动机(product DFA)、填表法
-
乘积自动机
状态集分别为Q,R,乘积DFA状态集为Q×R,[q,r],其中q∈Q,r∈R
注意:
-
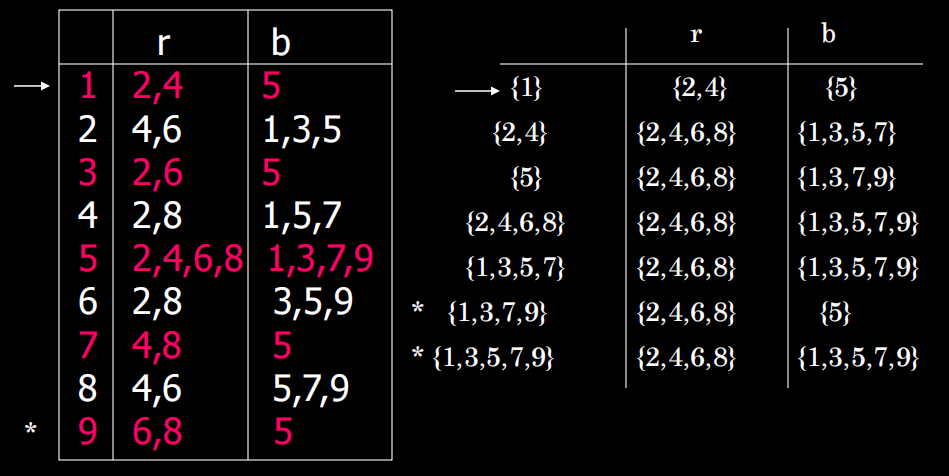
填表法
注意:当初始状态等价时,自动机等价
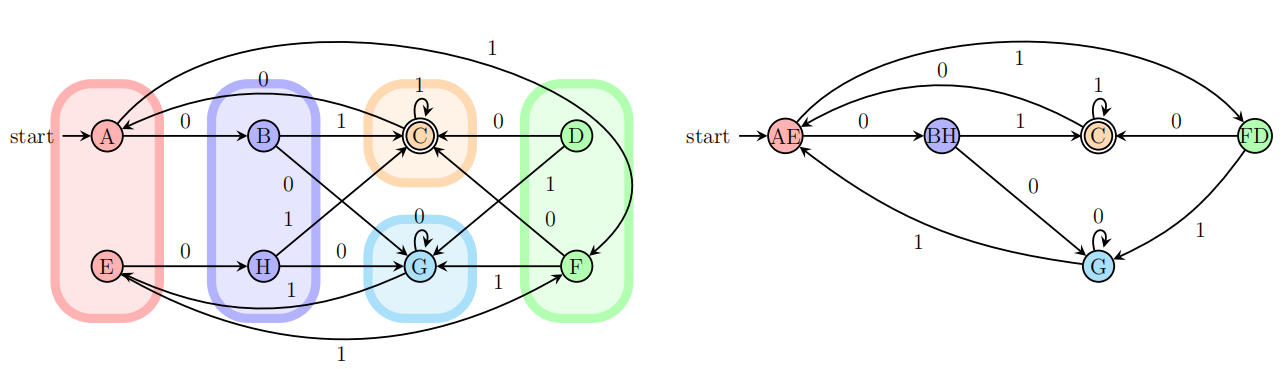
2.3 最小化Minimally
用于找出最少状态的DFA或最短长度的RE,方法:消除不可达状态,合并不可区分状态
填表法步骤示例:
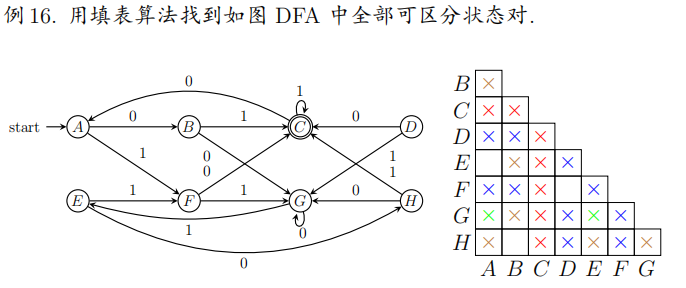
- 直接标记终态和非终态之间的状态对:{C}×{A,B,D,E,F,G,H}
- 标记所有经过字符 0 到达终态和非终态的状态对:{D,F}×{A,B,C,E,G,H}
- 标记所有经过字符 1 到达终态和非终态的状态对:{B,C,H}×{A,C,D,E,F,G}
- 检查剩下状态对:[A,G],[E,G]可区分
3.正则表达式
3.1 语言写正则表达式
分治法、递归、串接等方法设计正则表达式
L={w∣w∈{a,b,c}∗,且w至少包含一个a和一个b}
分a和b的先后顺序即可
c∗a(a+c)∗b(a+b+c)∗+c∗b(b+c)∗a(a+b+c)∗
L={w∣w∈{0,1}∗,且倒数第三个符号是1}
(0+1)∗1(0+1)(0+1)
L={w∣w∈{0,1}∗,w没有两个连续的0}
对于此类问题,有两种方法:
-
利用式子∑∗=(0+1)∗,该式认为00101=((0)(0)(1)(0)(1))。我们只要让0产生的时候跟一个1即可,同时需要注意末尾和开头的0/1、以及满足空串的要求
(1+01)∗(0+ϵ)或(0+ϵ)(1+10)∗
-
利用式子∑∗=(0∗1∗)∗,该式子认为0011011=((00)(11))((0)(11))。同理我们产生0时加上1即可,同时需要注意空串和前后0/1的要求
1∗(011∗)∗(0+ϵ)
L={w∣w∈{0,1}∗,w没有两个连续的1}
参考上一问:
(0+10)∗(1+ϵ)或(1+ϵ)(0∗01)∗0∗
L={w∣w∈{0,1}∗,且w至多只有一对连续的1}
没有连续的1或者有一对连续的1
错误示范:
(0+10)∗(1+ϵ)+(1∗0+ϵ)11(01∗+ϵ)
正确示范:
(0+10)∗(1+ϵ)+(0+10)∗11(0+01)∗
L={w∣w∈{0,1}∗,且w有两对连续的1}
case 1: 111的形式
(0+10)∗111(0+01)∗
case 2:11…11的形式
(0+10)∗11(0+0(1+ϵ)(0+01)∗0)11(0+01)∗
L={w∣w∈{0,1}∗,w中每对相邻的0都在任何一对相邻的1前面}
问题等价为没有连续的1串接上没有连续的0
(0+10)∗(ϵ+1)(1+01)∗(0+ϵ)
L={w∣w∈{0,1}∗,w中不包含子串01}
1∗0∗
L={w∣w∈{0,1}∗,w中不包含子串10}
0∗1∗
3.2正则表达式写语言
较简单,无例题
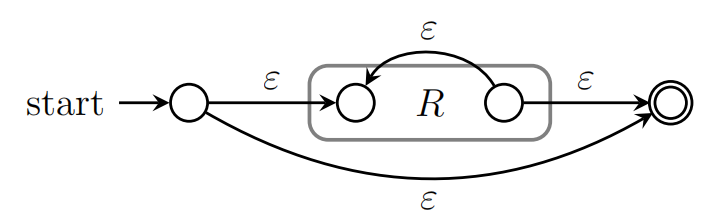
3.3(非考试)正则表达式转NFA
-
对于r+s,
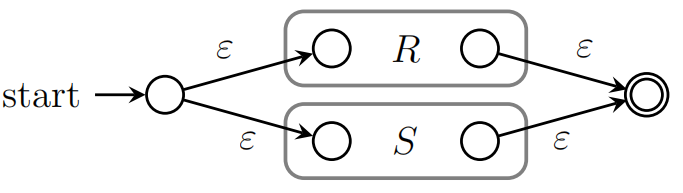
-
对于rs,有

-
对于r∗,有
4.上下文无关文法CFG
4.1 构造CFG
给出L={0n1n∣n≥0}的文法
S→0S1∣ϵ
给出L={0n1n∣n≥1}的文法
S→0A1A→0A1∣ϵ
给出L={0n1n0m1m∣n≥0,m≥0}的文法
S→AAA→0A1∣ϵ
给出L={0和自然数(不能以0开头)}
S→0∣ABA→1∣2∣3∣4∣5∣6∣7∣8∣9B→CB∣ϵC→0∣A
给出L={0n1m0m1n∣n≥0,m≥0}的文法
S→0S1∣ϵ∣AA→1A0∣ϵ
为语言L={0n1m∣n=m}设计文法
分为n>m和n<m两种情况
即00 000 111和000 111 11
S→AC∣CBA→A0∣0C→0C1∣ϵB→1B∣1
给出L={x∣x包含两个相同的全0子串}的文法
考虑分为三部分,Eg. (1001)(00110100)(10110)
S→ABCA→ϵ∣U1U→0U∣1U∣ϵC→1U∣ϵB→0B0∣0D0D→1U1∣1
给出L={w∈{0,1}∗∣w包含至少3个1}的文法
S→A1A1A1AA→0A∣1A∣ϵ
给出Leq={w∈{0,1}∗∣w中0和1个数相等}的文法
S→0S1∣1S0∣ϵ∣SS,寻找递归结构,用变量构造
S→S0S1S∣S1S0S∣ϵ,目标串这样构成,由变量定义变量
S→0B∣1AA→0∣0S∣1AAB→1∣1S∣0BB
给出L1={wwR∣w∈{0,1}∗}的文法
S→0S0∣1S1∣ϵ
给出L={w∣w=wR,w∈{0,1}∗}的文法
S→0S0∣1S1∣0∣1∣ϵ
给出L={aibjck∣i=j或j=k}的文法
A/D产生0个及以上的a/c,E产生1个及以上的b
B先产生相同数量的b,c,然后要么产生≥1的b,要么产生≥1的c;C同理
因此AB代表j=k,CD代表i=j
S→AB∣CDA→aA∣εB→bBc∣E∣cDC→aCb∣E∣aAD→cD∣εE→bE∣b
给出L={w∈{0,1}∗∣w不是ww形式}的文法
O生成奇数长度的串(一定不是ww形式),E生成偶数长度的串
将E分为左右长度相等的串wl和wr,最坏情况下只存在一个位置有wl[i]=wr[i]
我们以这个位置为中心,进行左右推导,即使左右推导的结果相等,最终的串也不相等
S→E∣OO→0∣1∣COCE→AB∣BAA→CAC∣0B→CBC∣1C→0∣1
给出L={w∈{0,1}∗∣0的个数是1的个数的两倍}的文法
S→S1S0S0S∣S0S1S0S∣S0S0S1S∣ϵ
4.2 推导CFG
给定字符串,写出其最左、最右或最短的推导
给定文法
S→A1BA→0A∣ϵB→0B∣1B∣ϵ
给出串00101的最左/右推导
最左:S→A1B→0A1B→00A1B→001B→0010B→00101B→00101
最右:S→A1B→A10B→A101B→A101→0A101→00A101→00101
4.3 画语法树
给定字符串及文法规则,画出语法树。和4.1最左/右推导一致,不再给出例题
4.4 二义性
如果CFG能为某个句子生成多颗语法解析树,则称CFG是二义的( ambiguous )
如果题目要求证明文法具有二义性:给出两颗不同的语法解析树即可
5.下推自动机PDA
5.1 设计PDA
接受可以写成空栈方式ϵ,Z0/ϵ或终结状态方式ϵ,Z0/Z0
设计识别L01={0n1n∣n≥1}的PDA
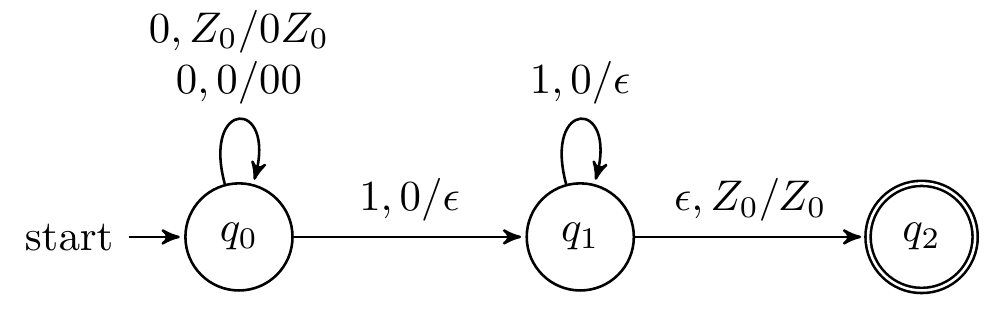
L01识别符号串0011的动作序列?
(q0,0011,Z0)⊢(q0,011,0Z0)⊢(q0,11,00Z0)⊢(q1,1,0Z0)⊢(q1,ϵ,Z0)⊢(q2,ϵ,Z0)
设计识别Lwwr={wwR∣w∈(0+1)∗}的PDA
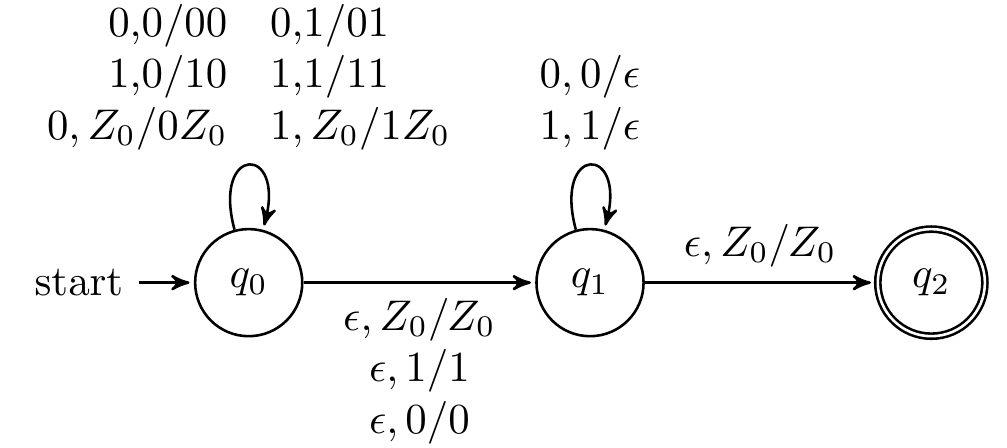
设计识别Lw#wr={w#wR∣w∈(0+1)∗}的PDA
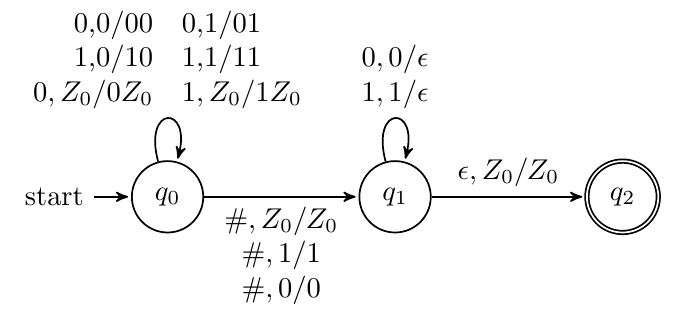
接受L={w:w=wR∣w∈(0+1)∗}的PDA
对于奇数长度的串,选择跳过中间的0或1;对于偶数,不跳过(采用空转移实现)

接受L={w∈{0,1}∗∣w中0和1的数量相同}的PDA
对于01数量均为n的串,一定存在n个不相交的01匹配,因此可以用不确定的PDA实现
最后的ϵ,Z0/ϵ是将栈底符号弹出,实现以空栈状态接受w
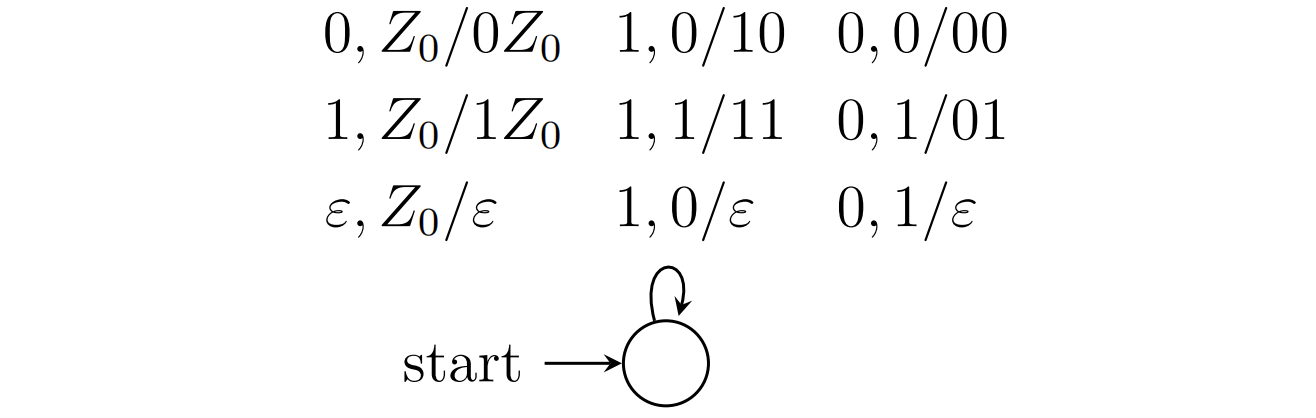
接受L={0n1m∣0≤n≤m≤2n}的PDA
由于每个0都对应1个1或者2个1,可以考虑将所有的0压栈,可以识别2个1再弹出0也可以识别出1个1再弹出0。对于识别2个1弹出0,我们增加一个状态,第一个1不弹0,第二个1弹出0
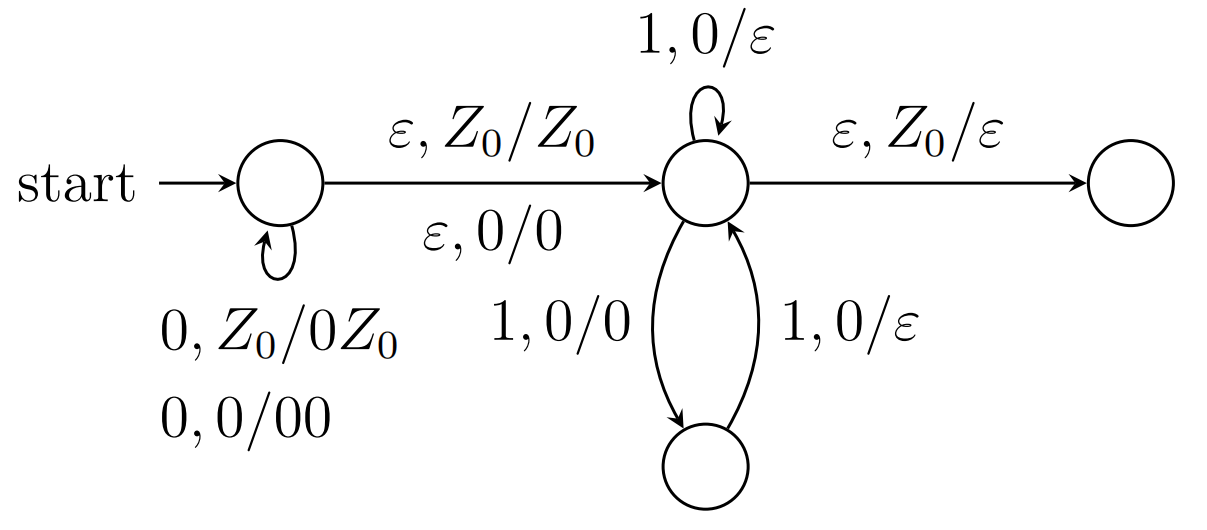
设计语言L={0n1m∣1≤m≤n}的PDA
不出现1,Z0即可
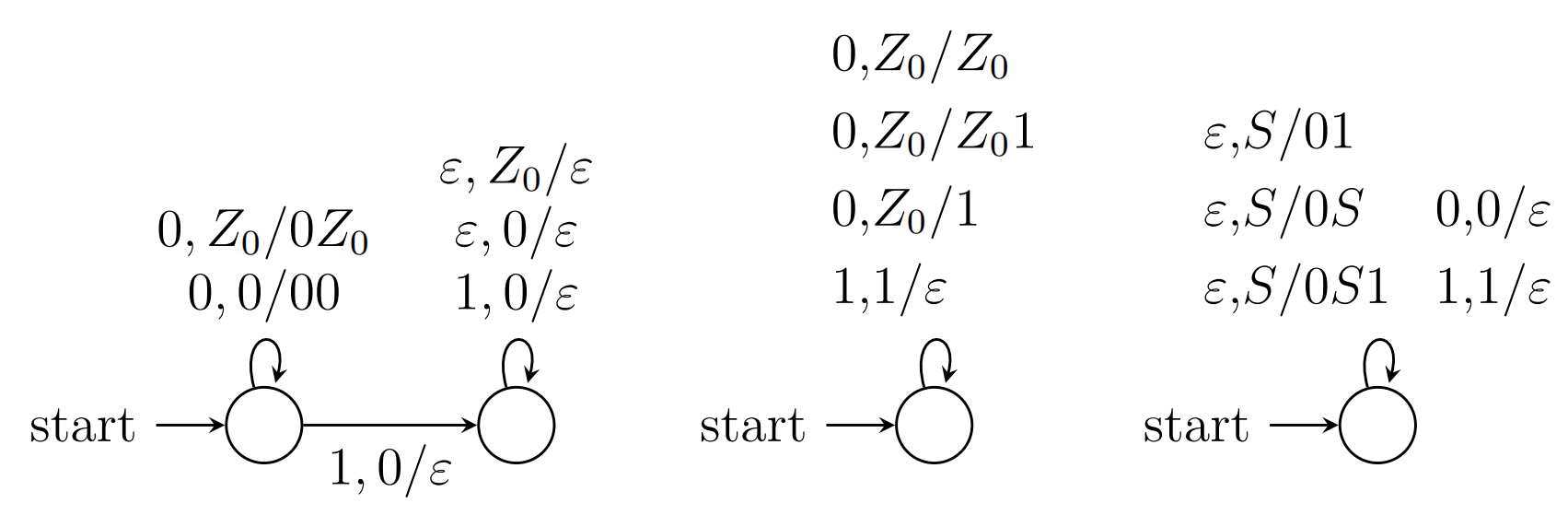
接受L={0n1m0m1n∣n≥0,m≥0}的PDA
0压栈,1压栈,0弹出,1弹出,设计四个状态即可
接受L={w∣w包含两个相同的全0子串}的PDA
参考上文的CFG,(…1)(0…0)(1…1)(0…0)(1…)

5.2 根据CFG构造PDA
当PDA比较难写出来时,采用CFG转PDA的方法
如果CFG G=(V,T,P′,S),构造PDA
P=({q},T,V∪T,δ,q,S,ϕ)
其中δ为:
- ∀A∈V:δ(q,ϵ,A)={(q,β)∣A→β∈P′}
- ∀a∈T:δ(q,a,a)={(q,ϵ)}
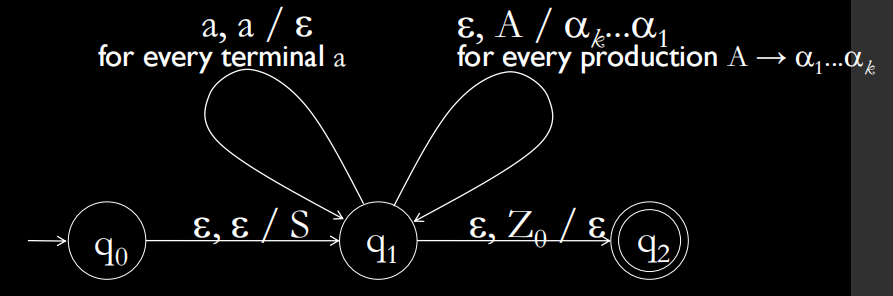
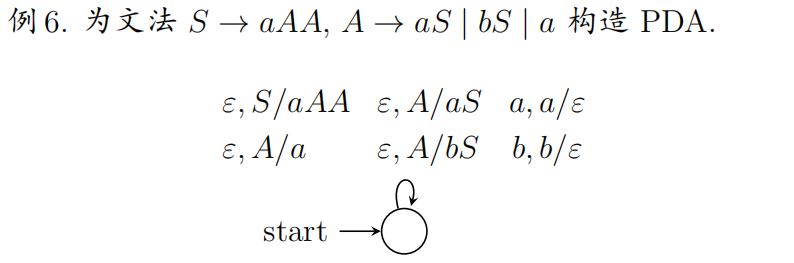
6.泵引理(RL/CFL)
6.1 RL的泵引理
用于证明一个语言不是正则语言,泵引理如下:
如果语言 L 是正则的*,* 那么存在正整数 N,对∀w∈L,
只要∣w∣≥N, 就可以将 w 分为三部分 w=xyz 满足:
- 采用”对抗赛“的方式证明,方便书写
下表中用len(w)表示∣w∣,因为markdown表格会识别’|'符号…
证明L01={0n1n∣n≥0}不是正则语言
证明Leq={w∣w由数量相等的0和1构成}不是正则的
| BOSS |
Me |
| 选取N∈Z+ |
选取w=0N1N,显然w∈L,len(w)=2N>N |
| 选取len(xy)≤N,则y=0m且m≥1 |
选取i=2,则xy2z=0N+m1N∈L01(Leq) |
|
不满足泵引理,因此不是正则语言 |
证明L={0i1j∣i>j}不是正则的
| BOSS |
Me |
| 选取N∈Z+ |
选取w=0N+11N,显然w∈L,len(w)=2N+1>N |
| 选取len(xy)≤N,则y=0m且m≥1 |
选取i=0,则xy0z=0N+1−m1N∈L |
|
不满足泵引理,因此不是正则语言 |
证明L={a3bncn−3∣n≥3}不是正则语言
| BOSS |
Me |
| 选取N∈Z+ |
选取w=a3bNcN−3,显然w∈L,len(w)=2N>N |
| 选取len(xy)≤N,则有三种情况:y=am或y=bm或y=albr |
①选取i=2,则xy2z=a3+mbNcN−3∈L .②选取i=2,则xy2z=a3bN+mcN−3∈L.③选取i=2,则xy2z=a3bralbNcN−3∈L |
|
三种情况都不满足泵引理,因此不是正则语言 |
证明L={0n10n1∣n≥0}不是正则语言
| BOSS |
Me |
| 选取N∈Z+ |
选取w=0N10N1,显然w∈L,len(w)=2N+2>N |
| 选取len(xy)≤N,则y=0m且m≥1 |
选取i=0,则xy0z=0N−m10N1∈L |
|
不满足泵引理,因此不是正则语言 |
证明L={1p∣p是素数}不是正则语言
| BOSS |
Me |
| 选取N∈Z+ |
选取w=1P,P是大于N的最小素数,显然w∈L,len(w)=P>N |
| 选取len(xy)≤N,则y=1b且b≥1,xyz=1a1b1c |
选取i=a+c,则xya+cz=1a+b(a+c)+c=1(a+c)(1+b)∈L |
|
不满足泵引理,因此不是正则语言 |
判断L={1p∣p能被3整除}是否是正则的
1P是正则的,1P=(111)∗
以下为错误示范:xy4b+1z=1a+c+4b+1
| BOSS |
Me |
| 选取N∈Z+ |
选取w=1P,P是大于N的最小的3的倍数,显然w∈L,len(w)=P>N |
| 选取len(xy)≤N,则y=1b且b≥1,xyz=1a1b1c |
选取i=4b+1,则xy4b+1z=1a+c+4b+1,由于a+b+c=3k,k∈N+,因此1a+c+4b+1=13(k+b)+1∈L |
|
不满足泵引理,因此不是正则语言 |
证明L={0n∣n是完全平方数}不是正则的
| BOSS |
Me |
| 选取N∈Z+ |
选取w=0P,P是大于N的最小的完全平方数,P=K2,显然w∈L,len(w)=P>N |
| 选取len(xy)≤N,则y=0b且b≥1,xyz=0a0b0c |
选取i=b+P,则xyb+Pz=0a+c+b+P=02P=02K2,由于2K2不是完全平方数,因此xyb+Pz∈L |
|
不满足泵引理,因此不是正则语言 |
证明L={0n∣n是完全立方数}不是正则的
| BOSS |
Me |
| 选取N∈Z+ |
选取w=0P,P是大于N的最小的完全立方数,P=K3,显然w∈L,len(w)=P>N |
| 选取len(xy)≤N,则y=0b且b≥1,xyz=0a0b0c |
选取i=b+P,则xyb+Pz=0a+c+b+P=02P=02K3,由于2K3不是完全平方数,因此xyb+Pz∈L |
|
不满足泵引理,因此不是正则语言 |
证明L={0n∣n是2的幂}不是正则的
| BOSS |
Me |
| 选取N∈Z+ |
选取w=0P,P是大于N的最小的2的幂次,P=2K,显然w∈L,len(w)=P>N |
| 选取len(xy)≤N,则y=0b且b≥1,xyz=0a0b0c |
选取i=2,则xy2z=0P′,由于P<P′≤P+N<2P,2P是大于P的下一个2的幂次数字,因此xy2z∈L |
|
不满足泵引理,因此不是正则语言 |
6.2 CFL的泵引理
大概率不考…
如果语言L是CFL,存在正整数N,对∀z∈L,只要∣z∣≥N,就可以将z分为五部分z=uvwxy,满足
- vx=ϵ(∣vx∣>0)
- ∣vwx∣≤N
- ∀i≥0,uviwxiy∈L
7.CNF/CYK算法
7.1 文法化简的顺序
-
消除ϵ−产生式
S→AB,A→AaA∣ϵ,B→BbB∣ϵ
A、B是可空的,因此S→AB∣A∣B,A→AaA∣Aa∣aA∣a,B→BbB∣Bb∣bB∣b
-
消除单元产生式
若有A→B,则称[A,B]为单元对,删除A→B,然后将B的产生式复制给A
-
消除非产生的无用符号
A→α,且α中符号都是产生的,则A是产生的
-
消除非可达的无用符号
S是可达的,A→α,且A是可达的,则α中符号都是可达的
7.2 CNF化简算法
每个不带 ε 的 CFL 都可以由这样的 CFG G 定义*,* G 中每个产生式的形式都为A→BC 或 A→a
这里的 A,B和C 是变元,a 是终结符
转换方法:
-
将产生式A→X1X2...Xm中的终结符a替换为新变元Ca
-
增加新产生式Ca→a
-
引入新变元D1,D2,...,Dm−2,将产生式A→B1B2...Bm替换为级联产生式
A→B1D1D1→B2D2...Dm−2→Bm−1Bm
将下面的CFG写成CNF
S→ϵ∣ADDA
A→a
C→c
D→bCb
S′→S∣ϵ
S→AE,E→DF ,F→DA
A→a ,B→b,C→c
D→BG,G→CB
CFG G=({S,A,B},{a,b},P,S),产生式集合P为:
S→bA∣aB
A→bAA∣aS∣a
B→aBB∣bS∣b
请设计等价的CNF
S→CbA∣CaB,Cb→b,Ca→a
A→CbD1∣CbS∣a,D1→AA
B→CaD2∣CbS∣b,D2→BB
7.3 CYK成员性测试算法
CYK算法用来对CNF文法进行成员性测试,例子如下:Xij代表第i个到第j个字母区间

举个例子,判断X14(bbab)时,检查如下,其中×代表笛卡尔积
- X11×X24={BS,BC},在表中查找是否属于产生式,这里找到S产生BC
- X12×X34={},空集跳过
- X13×X44={AB},找到S和C都产生AB
因此答案X14={S,C}
8.构造图灵机
注意:画自动机时,可以先画出第一次循环,后面再补上循环缺失的转移
8.1 四则运算
加法、减法、乘法、乘方
加法
输入:B000C00B
输出:B00000B
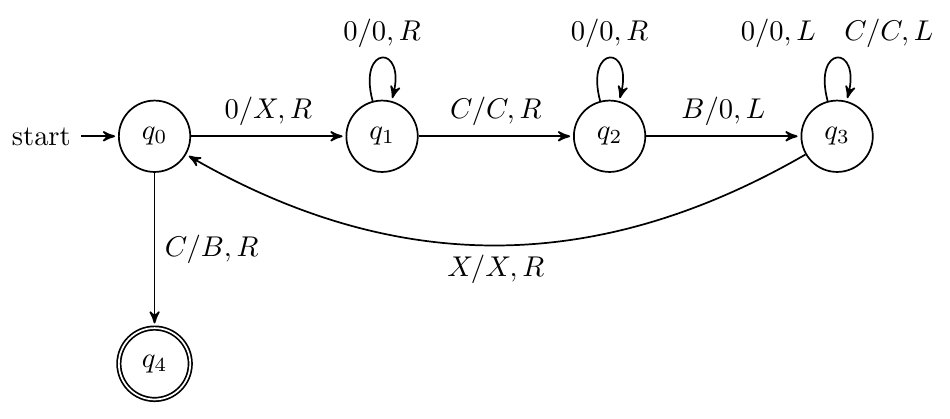
整数真减法
输入:B000100B 输出:B0B
输入:B00010000B 输出:B
这里采用1作为隔断,输出为前面的0数量-后面的0数量
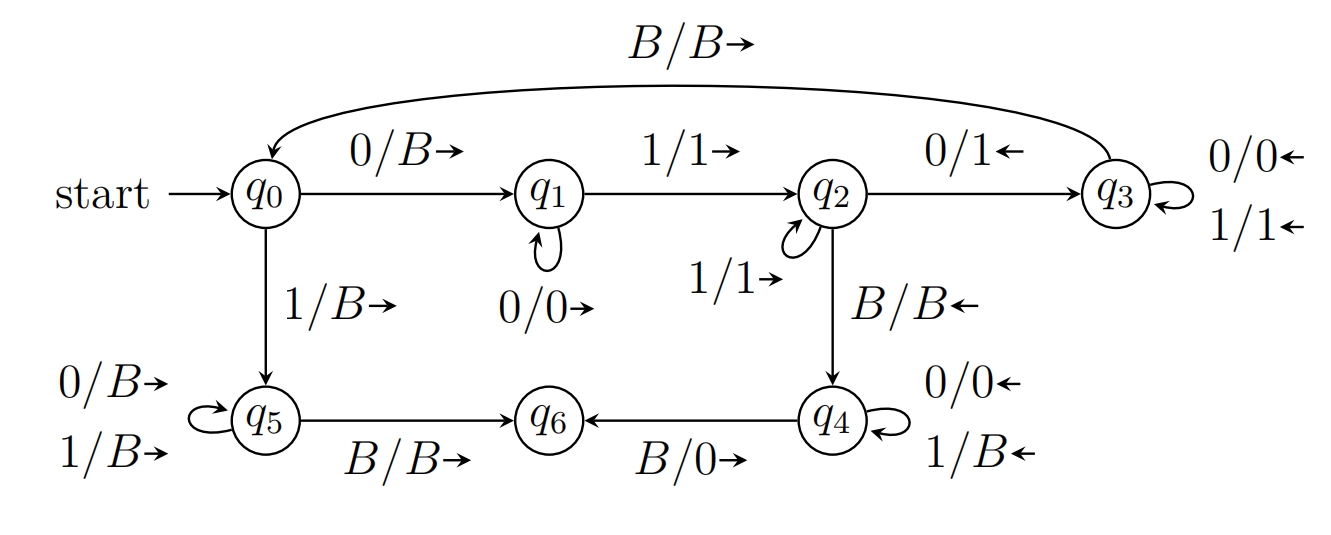
以000100(3-2)为例,以初始的1为界限,我们不断采用将1左边最远的0标记为B,1右边最近的0标记为1的操作
直到
-
发现1右边没有0了(即跳过1后遇到B),说明满足m≥n且n标记完了,此时我们1左边是多标记了一个0为B的
因此需要往左把标记的1变为B,只保留1前面的0,并且把最左边的一个B改为0(因为多标记了)
-
发现前缀0没有了,只剩下开始用来隔断的1,说明m<n,因此往右把所有的01转B即可
乘法
输入:B000C00B
输出:B000000B
太难了 建议抄在纸上T_T
- q0到q3将B000C00B变为B000C00C,并将新的字符串放在末尾的C后
- 思路:针对两个C之间的0,我们从左往右,每标记一个,就在末尾C后面复制开头B和中间C之间的0,即q5到q10实现转换为BYYYCX0C000B,q5到q3将前面的Y转换回来,准备下一轮的复制,即变为B000CX0C000B
- q3遇到末尾C则代表乘法完成,结果存放在末尾C后面,需要将末尾C和前面的C/X/0标记回B(即图中q3到q12,画的有点问题)
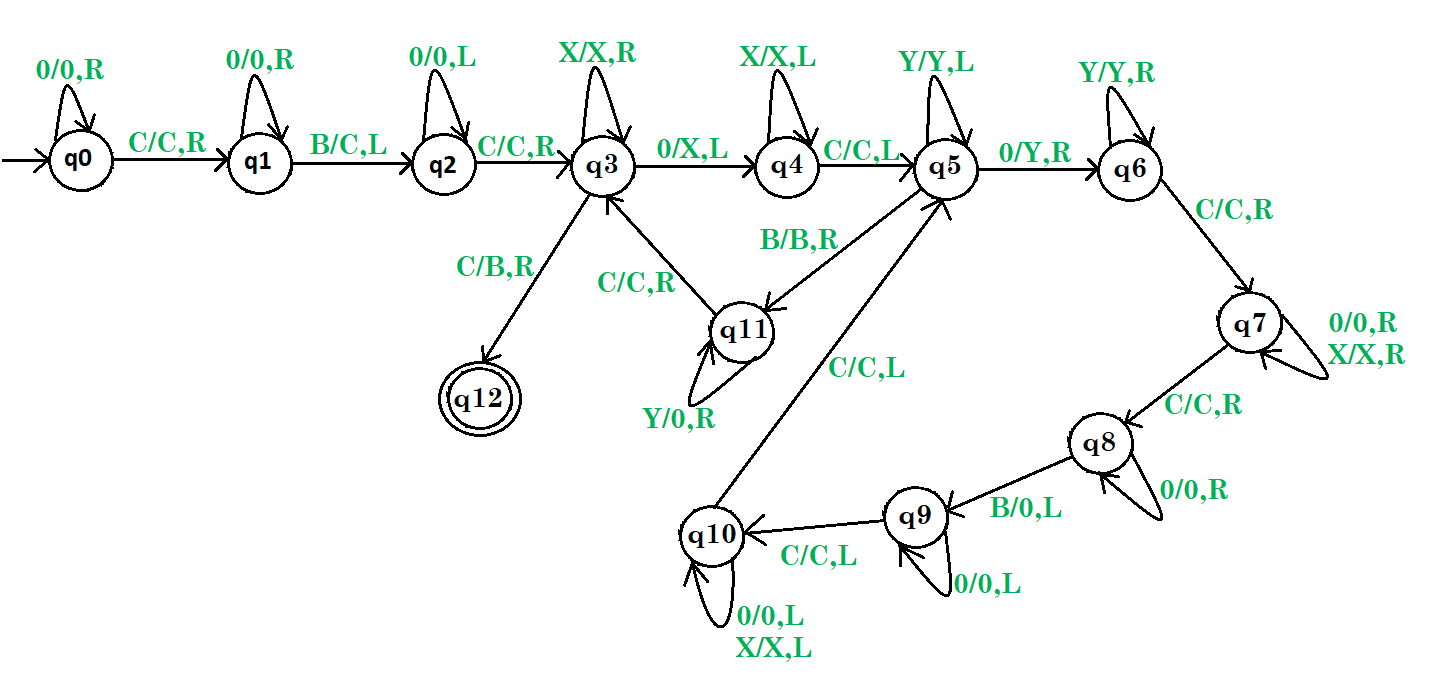
8.2 字符串操作
移动、复制、查找、反转
复制字符串:
输入:B10110B
输出:B10110C10110B
比较简单,分01讨论即可,最后别忘了把前面标记的01标记回去(不画图了^ _ ^,下图来源)

反转字符串
输入:B10110B
输出:B01101B
从右往左标记,分01讨论即可
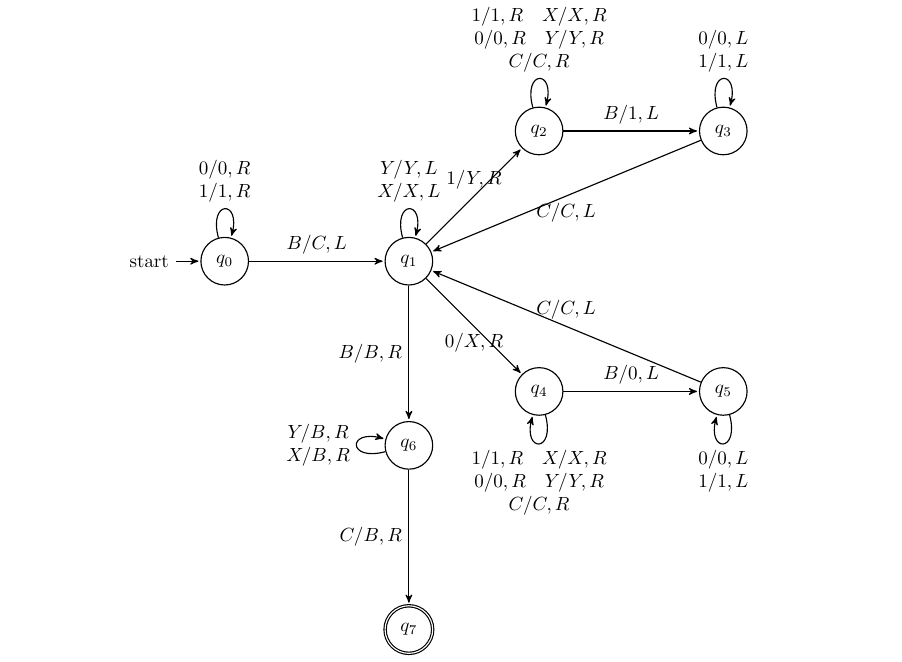
8.3 特定排列
设计识别{0n1n∣n≥1}的图灵机
思路:我们找出每一对匹配的0和1,将其标记为X和Y,当所有都标记完成则接受该字符串
即B000111B→BX00Y11B→BXX0YY1B→BXXXYYYB
建立循环如下,
- 识别到0,将其改为X并往右移动
- 跳过中间所有的0和Y(一直往右)
- 识别到1,改为Y往左移动
- 跳过中间所有的Y和0(一直往左)
- 找到X后往右移动,此时回到循环开头
如果在循环开头遇到Y,则说明01对已经标记完,则跳过所有的Y找到B,就进入了终结状态
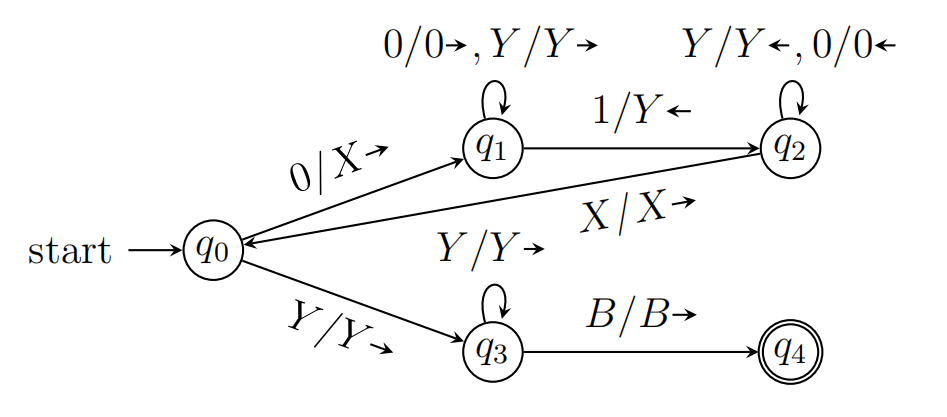
此图灵机接受0011的ID序列是?
q00011 ⊢Xq1011 ⊢X0q111 ⊢Xq20Y1 ⊢q2X0Y1 ⊢Xq00Y1 ⊢XXq1Y1 ⊢XXYq11 ⊢XXq2YY ⊢Xq2XYY ⊢XXq0YY ⊢XXYq3Y ⊢XXYYq3B ⊢XXYYBq4B
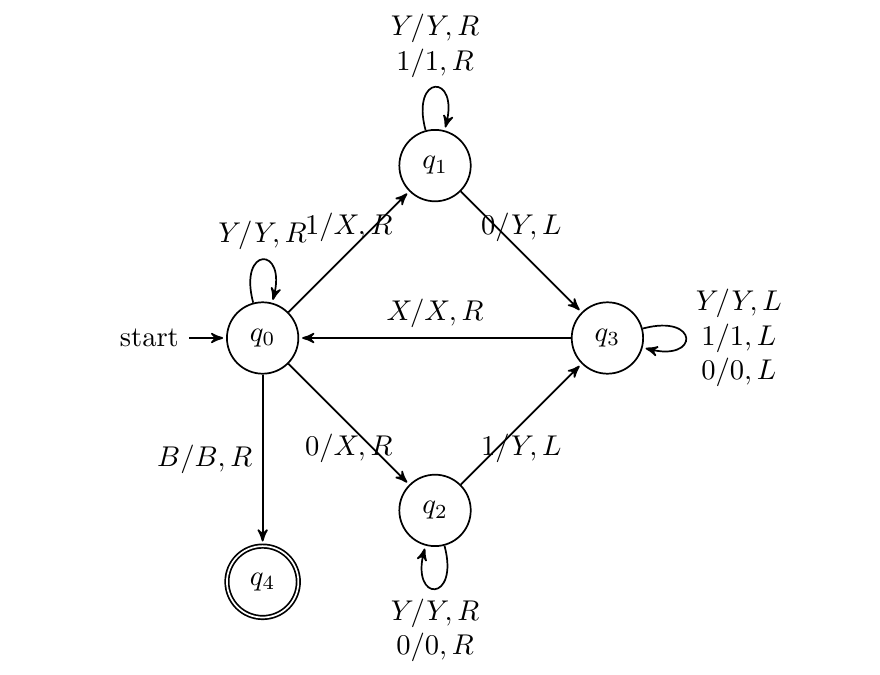
构造TM识别L={w∈{0,1}∗∣w中01的数量相等}
由于w中的01一定匹配,我们从左往右,不断找到一对01匹配项,对于左边的每个0/1,标记为为X,找到右边匹配的1/0标记为Y
因此最新的X(位于q0处,且是最左边的X)的左边一定都标记完成,右边一定只剩下Y;当跳过Y遇到B时,则接受该字符串
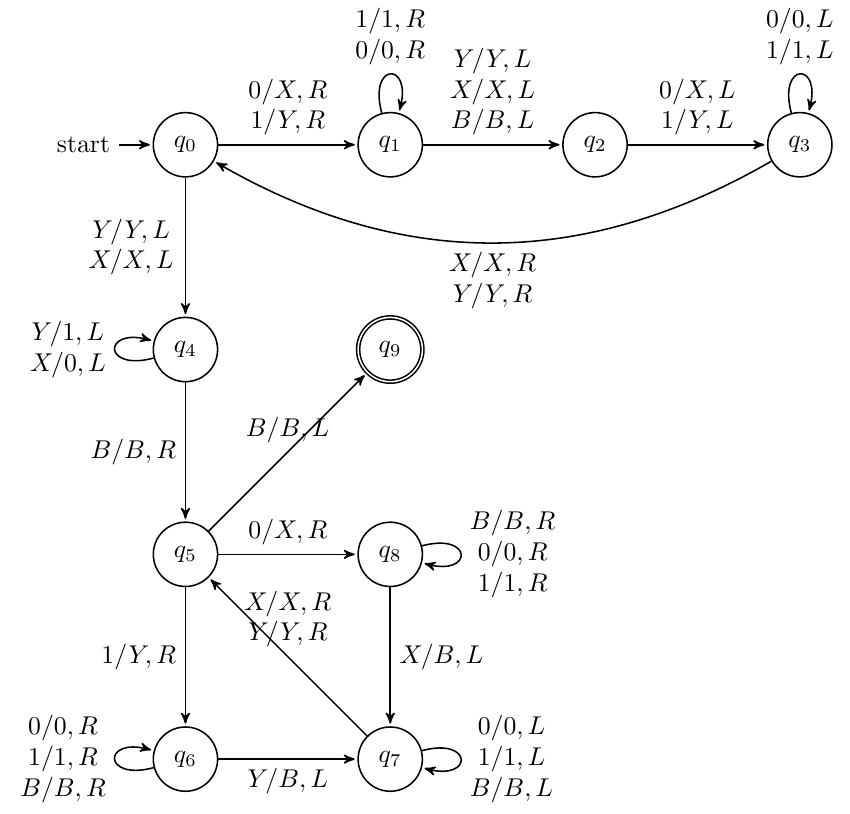
构造TM识别L={ww∣w∈{0,1}∗}
分为两步,以B01110111B作为例子,
-
找到中点:我们不断填充左边和右边,最终指针停在BXYYYXYYYB的位置
-
判断左边和右边:我们让指针左移一格,然后把左半边的XY还原为01,此时B0111XYYYB
然后不断标记左边,对右边进行判断即可,判断一个就标记为B。左边遇到B则进入终结状态
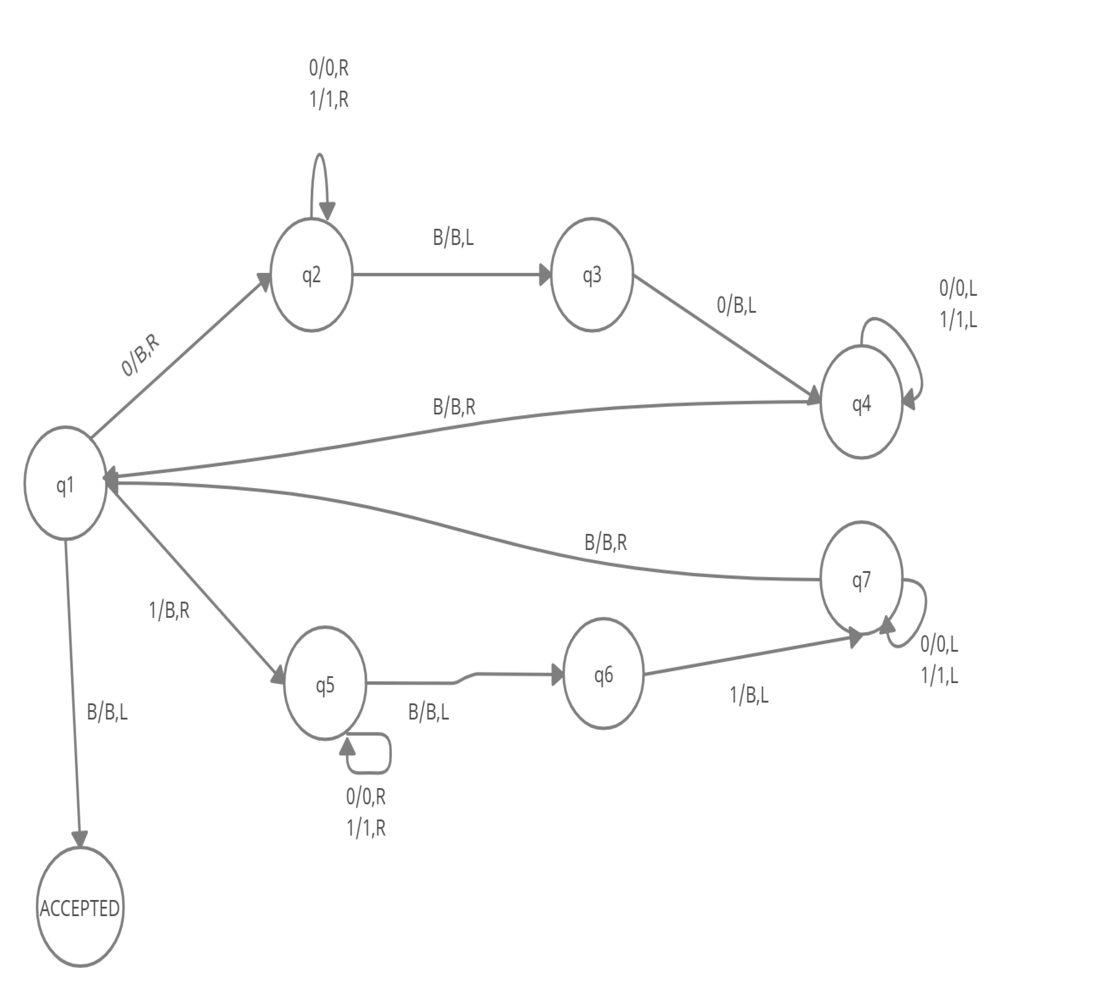
构造TM识别L={wwR∣w∈{0,1}∗}
分01讨论即可,从两端往中间标记
构造TM识别语言{anbncn∣n≥1}
每标记一个a(a/X),就往右移动匹配一个b(b/Y),再往右移动匹配一个c(c/Z),然后往左直到X,再往右,开始重复以上步骤。
注意,当a识别完(X往右遇到Y)时,需要检查是否所有的b和c都转为了Y和Z,是则接收,否则不接收。
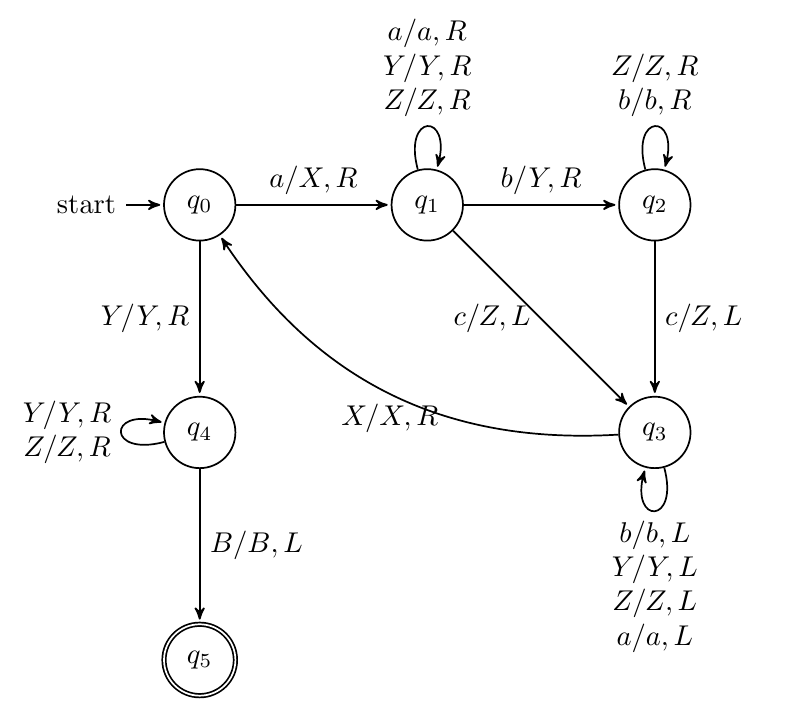
构造TM识别语言{anbmcn∣n≥m},其中n和m为正整数
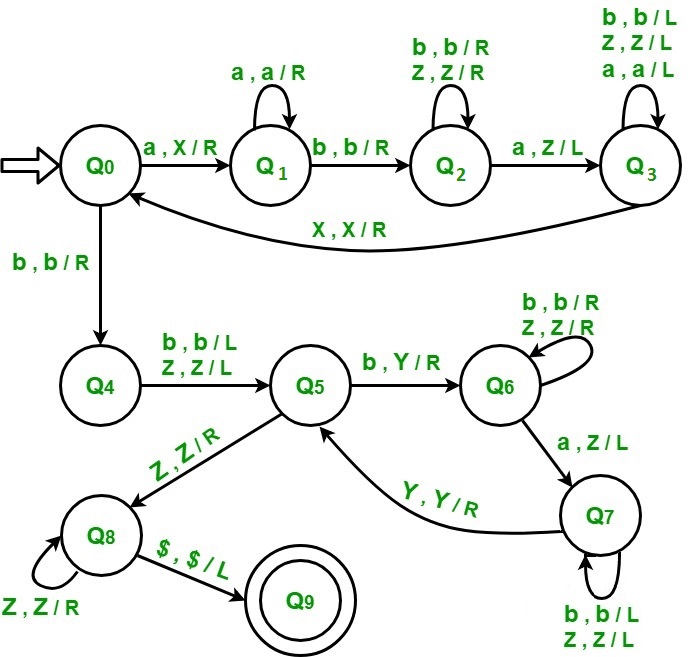
构造TM识别语言{anbman+m},其中n和m为正整数
先查找a,再查找b,都标记右边的a即可
构造TM识别语言{anb2n},其中n为正整数
每个a匹配两个b即可(a/X,b/Y),直到a识别完(遇到左端的Y),需要检查b是否识别完(Y结束后就是B)
9.讨论
9.1 不可判定性undecidable
对于一个问题,如果存在一个算法能回答它,则该问题是可判定的,即“可判定问题”=“递归语言”;否则是不可判定的
-
不可判定的问题:
- 是否会执行程序中的特定代码行?
- 给定的无上下文语法是否无二义?
- 两个给定 CFG 生成相同的语言吗?
- …
-
对角化语言Ld:不是递归可枚举语言,即不存在接受Ld的图灵机
-
通用语言Lu={M111w∣w∈L(M)}(图灵机M和输入串w的编码组成的有序对(M,w)):
递归可枚举(RE)但非递归的语言,即不可判定的
-
赖斯定理:令LP为TM M的二进制TM代码,满足L(M)具有属性P。
有两个属性可以判定:
- 不包含任何RE语言(判定为假)
- 包含每个RE语言(判定为真)
对于其他属性P,LP不可判定。
证明:采用归约的技术,将Lu归约到LP,由于Lu不可判定,因此LP不可判定
9.2 计算机设计computer design
9.3 程序语言设计programming language design